ZStack Cloud Platform
Single Server, Free Trial for One Year

Comprehensive product documentation and tools

Upholding the value of Customer First and the mission of Serving Customer, ZStack is dedicated to providing secure and stable services for customers.

To educate ZStack partners and interested individuals about cloud computing and to cultivate cloud computing talent.

ZStack provides innovative cloud infrastructure for ten major industries

The report provides three major
solutions and customer case studies for transitioning from VMware to ZStack.
On April 8 2024, Tencent Cloud’s authentication service experienced a major outage, rendering services dependent on login authentication, including the console, unavailable. This not only significantly damaged Tencent Cloud’s reputation but also impacted many people’s confidence in domestic public clouds.
Fortunately, Tencent yesterday released the Tencent Cloud April 8 Incident Post-Review and Report, which detailed the causes and process of the incident. This transparency allowed the incident to move beyond being a black box, enabling us to analyze the post-review from a technical perspective and understand why even a company as resource-rich as Tencent could experience such an incident.
Tencent Cloud’s Post-Mortem Analysis of the Service Outage
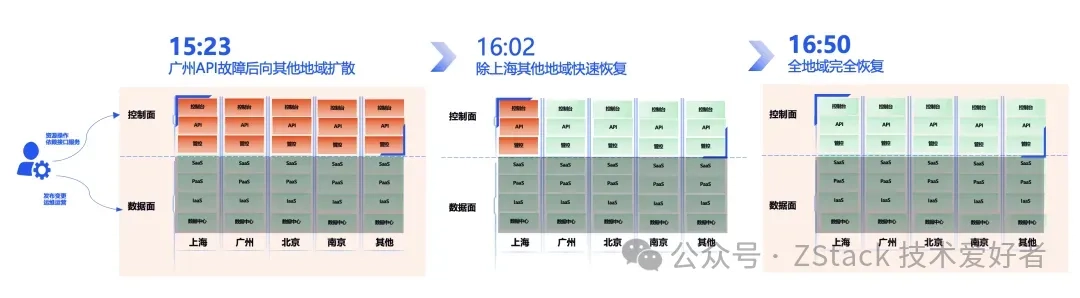
First, let’s examine the incident timeline provided by Tencent Cloud:
15:23: Detected the failure and immediately initiated service recovery while investigating root causes.
15:47: Found that version rollback failed to fully restore services, requiring further troubleshooting.
15:57: Identified the root cause as erroneous configuration data and urgently designed a data repair solution.
16:02: Initiated data restoration across all regions, with API services gradually recovering region by region.
16:05: Observed API service recovery in all regions except Shanghai, requiring focused troubleshooting on Shanghai.
16:25: Discovered API circular dependency issues in Shanghai’s technical components, deciding to reroute traffic to other regions for recovery.
16:45: Confirmed Shanghai region recovery with full restoration of API and dependent PaaS services, but console traffic surged requiring 9x capacity scaling.
16:50: Request volume normalized with stable operations and complete console service restoration.
17:45: Completed one-hour observation period with no issues detected, concluding the emergency response.
Root Cause Analysis by Tencent Cloud:
The outage resulted from inadequate forward compatibility considerations in the new cloud API version and insufficient gray release mechanisms for configuration data.
During API upgrade operations, interface protocol changes in the new version caused abnormal processing logic for legacy frontend data transmissions after backend deployment. This generated erroneous configuration data that rapidly propagated across all regions due to insufficient gray release controls, causing widespread API failures.
Post-failure recovery attempts followed standard rollback procedures, simultaneously reverting backend services and configuration data to previous versions with API service restarts. However, circular dependencies emerged as the container platform hosting API services itself required API functionality for scheduling capabilities, preventing automatic service recovery. Manual operator intervention was ultimately required to restart API services and complete restoration.
Two critical issues were identified:
Key questions remain: Why did Tencent Cloud encounter these issues? Public commentary frequently questions: “Given public cloud platforms’ inherent advantages for online gray testing, how could a global-scale outage still occur?”
Since the official postmortem analysis lacked detailed specifics, many aspects remain challenging to analyze conclusively. However, as a fellow ‘cloud platform developer’, I will share some potential underlying causes based on my experience:
Note that my perspective may carry biases from working primarily on enterprise software rather than online services, so readers are advised to consider multiple perspectives.
First, let’s define ‘microservices explosion’. As explained in an InfoQ-translated article titled 微服务——版本组合爆炸!(Microservices—Combinatorial Explosion of Versions!):
Let me explain this. Suppose our product consists of 10 microservices. Now assume each microservice has a new version (only one version, which sounds trivial). Looking at the product as a whole, with each component having one new version, we now have 2^10 combinations—1,024 permutations of our product.
Since there are no universally accepted ‘golden rules’ for splitting microservices, developers and teams often disagree on granularity and boundaries. This leads to excessive microservices proliferation in large systems, with each service following independent release cycles. Though solutions like Monorepo aim to optimize this, debugging and validating numerous microservices remains challenging.
A similar scenario occurred in late 2022 when Elon Musk tweeted about Twitter’s (now X, though still commonly referred to as Twitter) architecture, noting that “a single request traverses 1,200 microservice RPCs” as a cause of latency.

Elon Musk’s post
While an extreme case, this reflects a common reality: with abundant microservices and governance measures like circuit breaking and degradation, traffic control, and graceful shutdown—coupled with canary releases—developers often struggle to conduct comprehensive testing. Complacency creeps in, system complexity skyrockets, and risks go unnoticed until failure strikes (especially when proactive mitigation offers limited ROI).
Returning to this incident: a backend upgrade with an unupgraded frontend caused compatibility issues with legacy data structures. Such problems would not occur in a monolithic application—for example, you’d never encounter SQL errors from upgrading InnoDB without updating MySQL’s parser, as these components are upgraded and released together.
This isn’t to claim monolithic architectures are superior, but rather to highlight that version explosion becomes inevitable with excessive microservices. Traditional lib-based software also faces “dependency explosion,” but such complexity is hidden during build phases. Modern microservices, however, expose this complexity to operational stages.
Dependency hell
The reason we observed that rollback couldn’t timely rescue the platform was ‘cyclic dependency’ – even restarting the API backend requires the API service to be online first. In my view, this represents ‘the enormous risks of insufficiently analyzed automation’.
As IaaS developers, we deeply understand the extreme complexity of the underlying software we operate, thus constantly reminding ourselves ‘You Can’t Automate What You Don’t Understand‘. Our code essentially embodies business knowledge. If our understanding of business or underlying knowledge isn’t profound enough, we must never automate blindly, otherwise the outcome will only worsen.
However, it’s regrettable that whether driven by ‘requirements’ or ‘performance evaluation’, developers easily rush into automating things they don’t fully understand. As this incident demonstrates – service restart as developers’ ‘last-resort solution’ must achieve reduced dependencies and ensured reliability. Had developers known that the API service’s own restart depends on the API service, they likely wouldn’t have designed it this way. Yet regardless of reasons, it ultimately occurred.
Why does our architect emphasize this? Because technical support personnel under field/customer pressure often feel ‘I must do something now’, similar to developers/product teams thinking ‘this should be automated’. However, without understanding the real cause or underlying principles, rash actions might create bigger problems – just like Tencent Cloud’s case where restarting API services requires normal API services.”
Whether it was the epic-level failure of AWS’s S3 service in 2017, the large-scale service unavailability of a domestic ride-hailing app last year, or this Tencent Cloud outage, upgrade changes remain one of the main factors causing widespread failures. So how does ZStack address these issues?
This is ZStack Cloud‘s most fundamental architectural design. Through in-process microservices, we gain both the decoupling benefits of microservices and the operational/maintenance advantages of monolithic applications, organically combining microservices with monolithic architecture.
This feature has been available since ZStack Cloud 4.4 and was significantly enhanced in version 5.0. Through fine-grained gray upgrades, users can verify the status of services on each compute node and VPC router. Any abnormalities detected can be immediately rolled back, greatly increasing user confidence in upgrades. Detailed architecture and design of ZStack Cloud’s gray upgrade will be introduced in future articles.
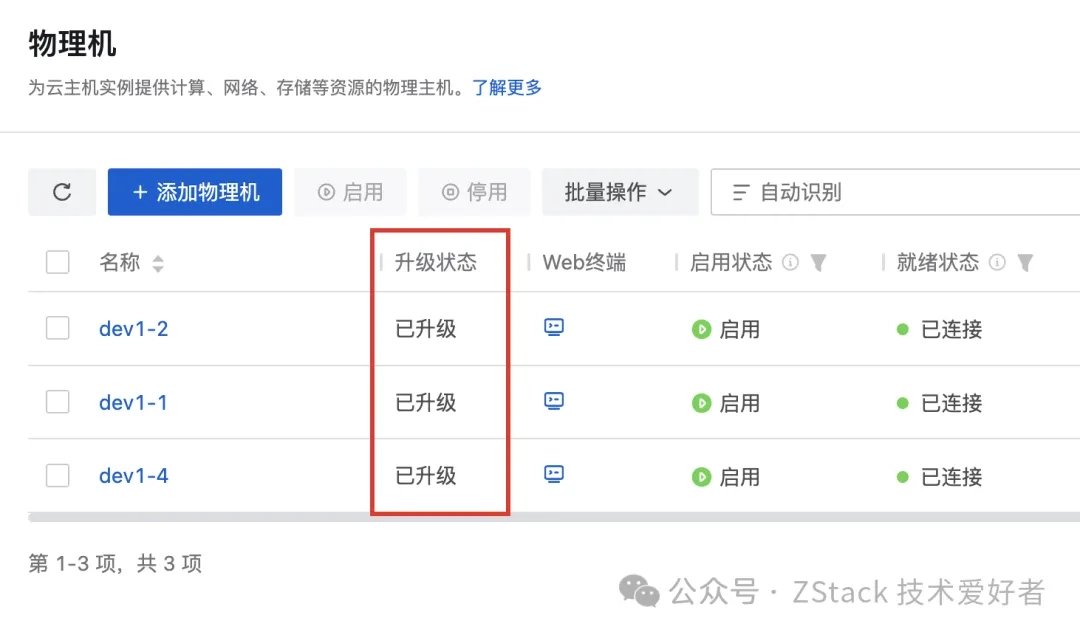
Compute Node Gray Upgrade Interface
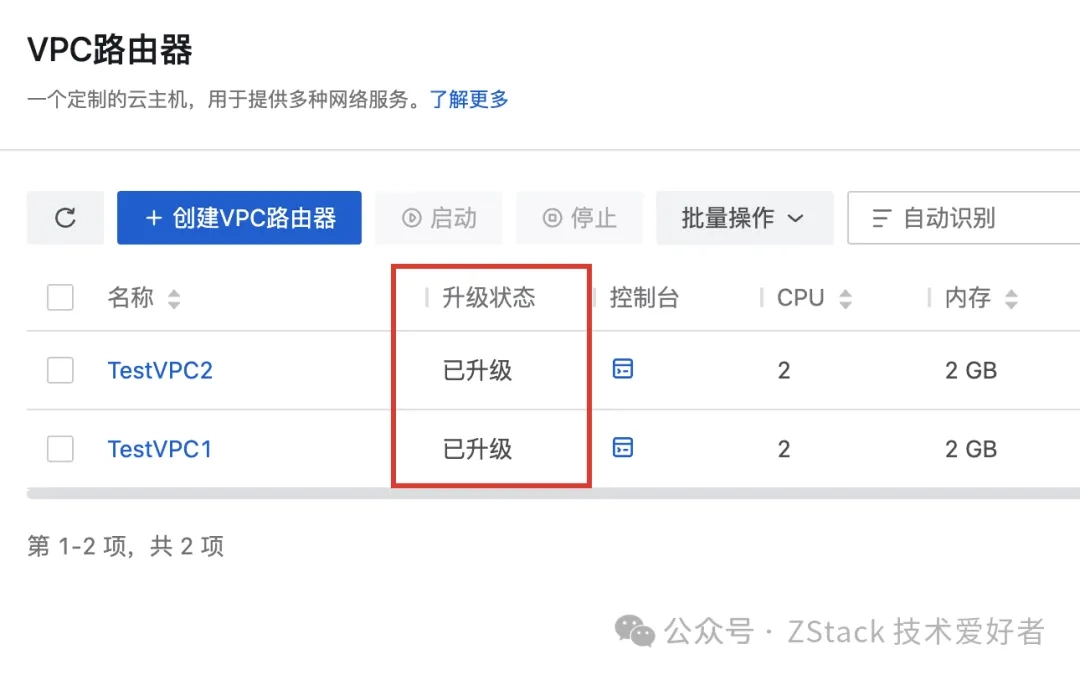
VPC Router Gray Upgrade Interface
As IaaS software, data plane reliability requirements exceed those of the control plane. The biggest concern for data plane reliability comes from virtualization components like libvirt and qemu. Particularly for qemu as the “carrier” of VMs, any misstep could directly cause user service interruptions. Therefore, ZStack provides hot upgrade capability for virtualization components, enabling users to perform in-place upgrades of running qemu versions locally without VM restarts or migrations.
Benefiting from stateless design, ZStack’s upgrade rollbacks have always been lightweight. Before upgrading, ZStack Cloud preserves core directories. Rollback only requires restoring the database and core directories. In special cases, simply ensuring correct software package versions on compute nodes maintains a final “escape route”.
Objectively speaking, regardless of design, software complexity and defects cannot be 100% avoided. Therefore, coordinated efforts across architectural design, coding implementation, test coverage, solution planning, and personnel experience remain essential. It’s precisely through such tight coordination that ZStack has continuously served over 3,500 clients over the years.
For more content about ZStack’s architectural design, follow ZStack News & Events. We will keep sharing more technical insights.
 2025-02-05
2024-12-12
2024-10-24
2024-09-21
2025-02-05
2024-12-12
2024-10-24
2024-09-21