ZStack Cloud Platform
Single Server, Free Trial for One Year

Comprehensive product documentation and tools

Upholding the value of Customer First and the mission of Serving Customer, ZStack is dedicated to providing secure and stable services for customers.

To educate ZStack partners and interested individuals about cloud computing and to cultivate cloud computing talent.

ZStack provides innovative cloud infrastructure for ten major industries

The report provides three major
solutions and customer case studies for transitioning from VMware to ZStack.
Due to the high cost of GPUs, especially high-end ones, companies often have this thought: GPU utilization is rarely at 100% all the time—could we split the GPU, similar to running multiple virtual machines on a server, allocating a portion to each user to significantly improve GPU utilization?
However, in reality, GPU virtualization lags far behind CPU virtualization for several reasons:
1. The inherent differences in how GPUs and CPUs work
2. The inherent differences in GPU and CPU use cases
3. Variations in the development progress of manufacturers and the industry

Today, we’ll start with an overview of how GPUs work and explore several methods for sharing GPU resources, ultimately discussing what kind of GPU sharing most enterprises need in the AI era and how to improve GPU utilization and efficiency.
1. Highly Parallel Hardware Architecture
A GPU (Graphics Processing Unit) was originally designed for graphics acceleration and is a processor built for large-scale data-parallel computing. Compared to the general-purpose nature of CPUs, GPUs contain a large number of streaming multiprocessors (SMs or similar terms), capable of executing hundreds or even thousands of threads simultaneously under a Single Instruction, Multiple Data (SIMD, or roughly SIMT) model.
2. Context and Video Memory (VRAM)
Context: In a CUDA programming environment, if different processes (or containers) want to use the GPU, each needs its own CUDA Context. The GPU switches between these contexts via time-slicing or merges them for sharing (e.g., NVIDIA MPS merges multiple processes into a single context).
Video Memory (VRAM): The GPU’s onboard memory capacity is often fixed, and its management differs from that of a CPU (which primarily uses the OS kernel’s MMU for memory paging). GPUs typically require explicit allocation of VRAM. As shown in the diagram below, GPUs feature numerous ALUs, each with its own cache space:

3. GPU-Side Hardware and Scheduling Modes
GPU context switching is significantly more complex and less efficient than CPU switching. GPUs often need to complete running a kernel (a GPU-side compute function) before switching, and saving/restoring context data between processes incurs a higher cost than CPU context switching.
GPU resources have two main dimensions: compute power (corresponding to SMs, etc.) and VRAM. In practice, both compute utilization and VRAM availability must be considered.
1. Mature CPU Virtualization with Robust Instruction Sets and Hardware Support
CPU virtualization (e.g., KVM, Xen, VMware) has been developed for decades, with extensive hardware support (e.g., Intel VT-x, AMD-V). CPU contexts are relatively simple, and hardware vendors have deeply collaborated with virtualization providers.
2. High Parallelism and Costly Context Switching in GPUs
Due to the complexity and high cost of GPU context switching compared to CPUs, achieving “sharing” on GPUs requires flexibly handling concurrent access by different processes, VRAM contention, and compatibility with closed-source kernel drivers. For GPUs with hundreds or thousands of cores, manufacturers struggle to provide full hardware virtualization abstraction at the instruction-set level as CPUs do, or it requires a lengthy evolution process.
(The diagram below illustrates GPU context switching, showing the significant latency it introduces.)

3. Differences in Use Case Demands
CPUs are commonly shared across large-scale multi-user virtual machines or containers, with most use cases demanding high CPU efficiency but not the intense thousands-of-threads matrix multiplication or convolution operations seen in deep learning training. In GPU training and inference scenarios, the goal is often to maximize peak compute power. Virtualization or sharing introduces context-switching overhead and conflicts with resource QoS guarantees, leading to technical fragmentation.
4. Vendor Ecosystem Variations
CPU vendors are relatively consolidated, with Intel and AMD dominating overseas with x86 architecture, while domestic vendors mostly use x86 (or C86), ARM, and occasionally proprietary instruction sets like LoongArch. In contrast, GPU vendors exhibit significant diversity, split into factions like CUDA, CUDA-compatible, ROCm, and various proprietary ecosystems including CANN, resulting in a heavily fragmented ecosystem.
In summary, these factors cause GPU sharing technology to lag behind the maturity and flexibility of CPU virtualization.
Broadly speaking, GPU sharing approaches can be categorized into the following types (names may vary, but principles are similar):
1. vGPU (various implementations at hardware/kernel/user levels, e.g., NVIDIA vGPU, AMD MxGPU, kernel-level cGPU/qGPU)
2. MPS (NVIDIA Multi-Process Service, context-merging solution)
3. MIG (NVIDIA Multi-Instance GPU, hardware isolation in A100/H100 architectures)
4. CUDA Hook (API hijacking/interception, e.g., user-level solutions like GaiaGPU)
Basic Principle: Splits a single GPU into multiple virtual GPU (vGPU) instances via kernel or user-level mechanisms. NVIDIA vGPU and AMD MxGPU are the most robustly supported official hardware/software solutions. Open-source options like KVMGT (Intel GVT-g), cGPU, and qGPU also exist.
Pros:
Flexible allocation of compute power and VRAM, enabling “running multiple containers or VMs on one card.”
Mature support from hardware vendors (e.g., NVIDIA vGPU, AMD MxGPU) with strong QoS, driver maintenance, and ecosystem compatibility.
Cons:
Some official solutions (e.g., NVIDIA vGPU) only support VMs, not containers, and come with high licensing costs.
Open-source user/kernel-level solutions (e.g., vCUDA, cGPU) may require adaptation to different CUDA versions and offer weaker security/isolation than official hardware solutions.
Use Cases:
Enterprises needing GPU-accelerated virtual desktops, workstations, or cloud gaming rendering.
Multi-service coexistence requiring VRAM/compute quotas with high utilization demands.
Needs moderate securityisolation but can tolerate adaptation and licensing costs.
(The diagram below shows the vGPU principle, with one physical GPU split into three vGPUs passed through to VMs.)

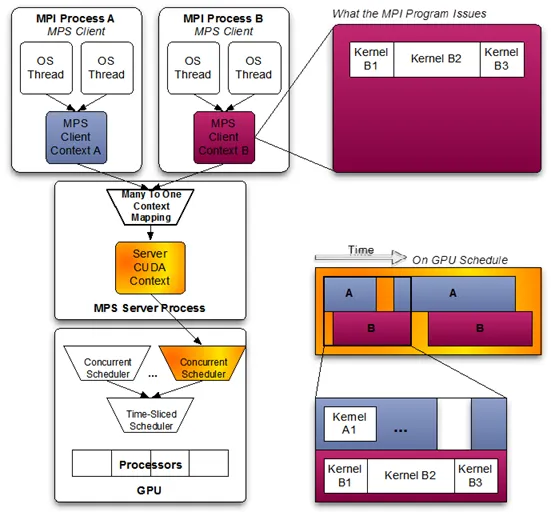
Basic Principle: An NVIDIA-provided “context-merging” sharing method for Volta and later architectures. Multiple processes act as MPS Clients, merging their compute requests into a single MPS Daemon context, which then issues commands to the GPU.
Pros:
Better performance: Kernels from different processes can interleave at a micro-level (scheduled in parallel by GPU hardware), reducing frequent context switches; ideal for multiple small inference tasks or multi-process training within the same framework.
Uses official drivers with good CUDA version compatibility, minimizing third-party adaptation.
Cons:
Poor fault isolation: If the MPS Daemon or a task fails, all shared processes are affected.
No hard VRAM isolation; higher-level scheduling is needed to prevent one process’s memory leak from impacting others.
Use Cases:
Typical “small-scale inference” scenarios for maximizing parallel throughput.
Packing multiple small jobs onto one GPU (requires careful fault isolation and VRAM contention management).
(The diagram below illustrates MPS, showing tasks from two processes merged into one context, running near-parallel on the GPU.)
Basic Principle: A hardware-level isolation solution introduced by NVIDIA in Ampere (A100, H100) and later architectures. It directly partitions SMs, L2 cache, and VRAM controllers, allowing an A100 to be split into up to seven sub-cards, each with strong hardware isolation.
Pros:
Highest isolation: VRAM, bandwidth, etc., are split at the hardware level, with no fault propagation between instances.
No external API hooks or licenses required (based on A100/H100 hardware features).
Cons:
Limited flexibility: Only supports a fixed number of GPU instances (e.g., 1g.5gb, 2g.10gb, 3g.20gb), typically seven or fewer, with coarse granularity.
Unsupported on GPUs older than A100/H100 (or A30, A16); legacy GPUs cannot benefit.
Use Cases:
High-performance computing, public/privateclouds requiring multi-tenant parallelism with strict isolation and static allocation.
Multiple users sharing a large GPU server, each needing only a portion of A100 compute power without interference.
(The diagram below shows supported profiles for A100 MIG.)

Basic Principle: Modifies or intercepts CUDA dynamic libraries (Runtime or Driver API) to capture application calls to the GPU (e.g., VRAM allocation, kernel submission), then applies resource limits, scheduling, and statistics in user space or an auxiliary process.
Pros:
Lower development barrier: No major kernel changes or strong hardware support needed; better compatibility with existing GPUs.
Enables flexible throttling/quotas (e.g., merged scheduling, GPU usage stats, delayed kernel execution).
Cons:
Fault isolation/performance overhead: All calls go through the hook for analysis and scheduling, requiring careful handling of multi-process context switching.
In large-scale training, frequent hijacking/instrumentation introduces performance loss.
Use Cases:
Internal enterprise or specific task needs requiring quick “slicing” of a large GPU.
Development scenarios where a single card is temporarily split for multiple small jobs to boost utilization.

Concept: Remote invocation (e.g., rCUDA, VGL) is essentially API remoting, transmitting GPU instructions over a network to a remote server for execution, then returning results locally.
Pros:
Enables GPU use on nodes without GPUs.
Theoretically allows GPU resource pooling.
Cons:
Network bandwidth and latency become bottlenecks, reducing efficiency (see table below for details).
High adaptation complexity: GPU operations require conversion, packing, and unpacking, making it inefficient for high-throughput scenarios.
Use Cases:
Distributed clusters with small-batch, latency-insensitive compute jobs (e.g., VRAM usage within a few hundred MB).
For high-performance, low-latency needs, remote invocation is generally impractical.
(The diagram below compares bandwidths of network, CPU, and GPU—though not perfectly precise, it highlights the significant gap, even with a 400Gb network vs. GPU VRAM bandwidth.)

With the rise of large language models (LLMs) like Qwen, Llama, and DeepSeek, model size, parameter count, and VRAM requirements are growing. A “single card or single machine” often can’t accommodate the model, let alone handle large-scale inference or training. This has led to model-level “slicing” and “sharing” approaches, such as:
1. Tensor Parallelism, Pipeline Parallelism, Expert Parallelism, etc.
Zero Redundancy Optimizer (ZeRO) or VRAM optimizations in distributed training frameworks.
2. GPU slicing for multi-user requests in small-model inference scenarios.

When deploying large models, they are often split across multiple GPUs/nodes to leverage greater total VRAM and compute power. Here, model parallelism effectively becomes “managing multi-GPU resources via distributed training/inference frameworks,” a higher-level form of “GPU sharing”:
For very large models, even slicing a single GPU (via vGPU/MIG/MPS) is futile if VRAM capacity is insufficient.
In MoE (Mixture of Experts) scenarios, maximizing throughput requires more GPUs for scheduling and routing, fully utilizing compute power. At this point, the need for GPU virtualization or sharing diminishes, shifting focus from VRAM slicing to high-speed multi-GPU interconnects.
1. Ultra-Large Model Scenarios
If a single card’s VRAM can’t handle the workload, multi-card or multi-machine distributed parallelism is necessary. Here, GPU slicing at the hardware level is less relevant—you’re not “dividing” one physical card among tasks but “combining” multiple cards to support a massive model.
(The diagram below illustrates tensor parallelism, splitting a matrix operation into smaller sub-matrices.)

2. Mature Inference and Training Applications
In production-grade LLM inference or training pipelines, multi-card parallelism and batch scheduling are typically well-established. GPU slicing or remote invocation adds management complexity and reduces performance, making distributed training/inference on multi-card clusters more practical.
3. Small Models and Testing Scenarios
For temporary testing, small-model applications, or low-batch inference, GPU virtualization/sharing can boost utilization. A high-end GPU might only use 10% of its compute or VRAM (e.g., running an embedding model needing just a few hundred MB or GBs), and slicing can effectively improve efficiency.
Remote invocation may suit simple intra-cluster sharing, but for latency- and bandwidth-sensitive tasks like LLM inference/training, large-scale networked GPU calls are impractical.
Production environments typically avoid remote invocation to ensure low inference latency and minimize overhead, opting for direct GPU access (whole card or sliced) instead. Communication delays from remote calls significantly impact throughput and responsiveness.

When single-card VRAM is insufficient, rely on model-level distributed parallelism (e.g., tensor parallelism, pipeline parallelism, MoE) to “merge” GPU resources at a higher level, rather than “slicing” at the physical card level. This maximizes performance and avoids excessive context-switching losses.
Remote invocation (e.g., rCUDA) is not recommended here unless under a specialized high-speed, low-latency network with relaxed performance needs.
For VMs, consider MIG (on A100/H100) or vGPU (e.g., NVIDIA vGPU or open-source cGPU/qGPU) to split a large card for multiple parallel tasks; for containers, use CUDA Hook for flexible quotas to improve resource usage.
Watch for fault isolation and performance overhead. For high QoS/stability needs, prioritize MIG (best isolation) or official vGPU (if licensing budget allows).
For specific or testing scenarios, CUDA Hook/hijacking offers the most flexible deployment.
Virtualizing GPUs via API remoting introduces significant network overhead and serialization delays. It’s only worth considering in rare distributed virtualization scenarios with low latency sensitivity.
The GPU’s working principles dictate higher context-switching costs and isolation challenges compared to CPUs. While various techniques exist (vGPU, MPS, MIG, CUDA Hook, rCUDA), none are as universally mature as CPU virtualization.
For ultra-large models and production: When models are massive (e.g., LLMs needing large VRAM/compute), “multi-card/multi-machine parallelism” is key, with the model itself handling slicing. GPU virtualization offers little help for performance or large VRAM needs. Resources can be shared via privatized MaaS services.
For small models like embeddings or reranking: GPU virtualization/sharing is suitable, with technology choice depending on isolation, cost, SDK compatibility, and operational ease. MIG or official vGPU offer strong isolation but limited flexibility; MPS excels in parallelism but lacks fault isolation; CUDA hijacking is the most flexible and widely adopted.
Remote invocation (API remoting): Generally not recommended for high-performance scenarios unless network latency is controllable and workloads are small.
Thus, for large-scale LLMs (especially with massive parameters), the best practice is distributed parallel models (e.g., tensor or pipeline parallelism) to “share” and “allocate” compute, rather than virtualizing single cards. For small models or multi-user testing, GPU virtualization or slicing can boost single-card utilization. This approach is logical, evidence-based, and strategically layered.
But how can we further improve GPU efficiency and maximize throughput with limited resources? If you’re interested, we’ll dive deeper into this topic in future discussions.
 2025-02-05
2024-12-12
2024-10-24
2024-09-21
2025-02-05
2024-12-12
2024-10-24
2024-09-21