ZStack Cloud Platform
Single Server, Free Trial for One Year

Comprehensive product documentation and tools

Upholding the value of Customer First and the mission of Serving Customer, ZStack is dedicated to providing secure and stable services for customers.

To educate ZStack partners and interested individuals about cloud computing and to cultivate cloud computing talent.

ZStack provides innovative cloud infrastructure for ten major industries

The report provides three major
solutions and customer case studies for transitioning from VMware to ZStack.
In the article Deep Understanding of DeepSeek and Enterprise Practices (Part 1): Distillation, Deployment, and Evaluation, we explored the distillation and quantization techniques of deep models, as well as the deployment basics of a 7B model. Typically, a single GPU’s memory can handle the full parameter requirements of a 7B model. However, when the parameter count scales up to the 32B (32 billion) level, a single GPU’s memory often falls short of supporting its full operation. This is where multi-GPU parallel inference becomes necessary, alongside considerations of whether the server’s hardware architecture can support multiple GPUs.
This article takes the deployment of DeepSeek-Distilled-Qwen-32B as an example. We’ll dive into the principles of multi-GPU parallelism and key considerations for deploying multiple GPUs in a server. Additionally, we’ll evaluate the 32B model’s runtime performance and reasoning capabilities, offering analysis and recommendations for its suitable use cases.
When deploying a 32B model, factors like precision, context length, and batch size significantly affect memory and computational demands. We covered the core influencing factors in the previous article, so we won’t repeat them here. Instead, we’ll directly provide the assessed values:
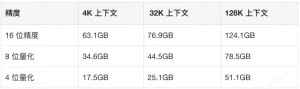
Given the complexity of modern quantization methods (e.g., data packing, FP8 format quantization, etc.), labeling them as Int8 or Int4 is less precise. Thus, we’ll use 8-bit quantization and 4-bit quantization for estimation here.
Additional variations may arise due to quantization strategies for different layers, data structure precision, whether KV Cache quantization is enabled, or the use of different inference frameworks.

From the calculations above, it’s clear that with large contexts—especially at higher data precision—a single GPU struggles to meet memory needs. Common consumer GPUs typically offer up to 24GB of memory, while inference-focused cards reach 48GB. Only a few high-end GPUs provide 64–141GB.
Thus, for models with 32B parameters or more, multi-GPU inference is nearly unavoidable. The main multi-GPU parallel strategies today are Tensor Parallelism and Pipeline Parallelism.
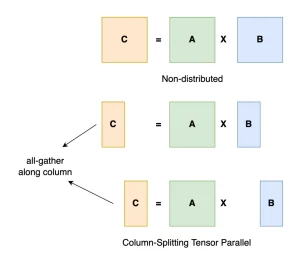
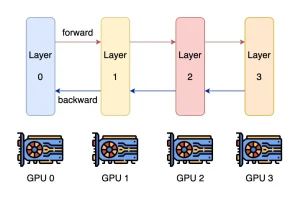
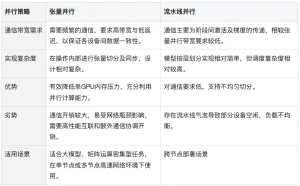
From the table above, Tensor Parallelism excels at boosting overall throughput. However, Pipeline Parallelism is simpler to implement and suits mixed CPU-GPU inference scenarios. This is why llama.cpp (the inference engine used by ollama) opts for Pipeline Parallelism. It also explains why llama.cpp’s multi-GPU performance is relatively weaker.
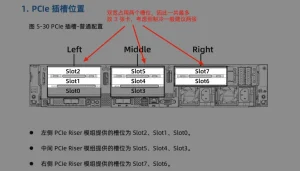
Most GPUs are double-width, occupying two PCIe slots. Even without other devices taking slots, a typical 2U server can only fit three GPUs. Since this doesn’t align with powers of 2, only two GPUs can be fully utilized.
Reduce Front-Panel Drive Count: Free up space and improve cooling by using larger-capacity drives instead of multiple smaller ones.
Use Multi-GPU Modules: Some server vendors offer dedicated GPU modules. These reserve the entire upper 1U space for GPUs, allowing up to 4 double-width GPUs side by side.

At this point, the front panel must reserve airflow for cooling. Thus, it can only hold 8 3.5-inch drives. Larger-capacity drives are needed to ensure sufficient storage.
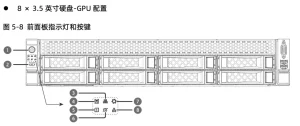
For more drives or better cooling, a 3U, 4U, or taller server is required. The optimal setup depends on cabinet power supply and GPU power consumption.
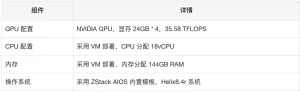
Deployment Steps
Performance Evaluation
Using ZStack AIOS Helix’s performance testing, we quickly assessed the model’s performance on current hardware. The data is summarized as follows:
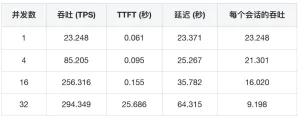
Combining these results, we can analyze the current environment:
Throughput (TPS) vs. Concurrency
Key Findings on Response Latency
Resource Efficiency Analysis
Recommended Configurations for Different Scenarios
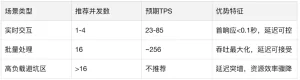
With ZStack AIOS Helix’s evaluation tools and real-world conditions, finding the right business plan and deployment model becomes easier.
Note: Tests show 16 concurrency as the optimal throughput/latency balance. Beyond this, performance degrades noticeably. Validate with stress tests based on hardware resources during actual deployment.
2. Evaluation Results
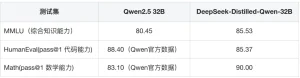
The 32B model excels in multiple areas:
Thus, we’ve identified potential use cases for DeepSeek-Distilled-Qwen-32B:
Through this exploration, we’ve gained deep insights into the multi-GPU deployment of DeepSeek-Distilled-Qwen-32B, hardware requirements, and performance across precision and parallel strategies. The 32B model’s robust capabilities open new possibilities for enterprise applications. Looking ahead, we anticipate seeing its value and potential in more real-world scenarios.
In future articles, we’ll cover:
By comparing models of varying sizes and precisions, we aim to provide comprehensive, detailed deployment plans for enterprise use. This will help industries adopt large language model technology quickly, unlocking business value.
Note: Some data in this article is illustrative. Actual conditions may vary. Detailed testing and validation are recommended during implementation.
 2025-02-05
2024-12-12
2024-10-24
2024-09-21
2024-10-10
2025-02-05
2024-12-12
2024-10-24
2024-09-21
2024-10-10