ZStack Cloud Platform
Single Server, Free Trial for One Year

Comprehensive product documentation and tools

Upholding the value of Customer First and the mission of Serving Customer, ZStack is dedicated to providing secure and stable services for customers.

To educate ZStack partners and interested individuals about cloud computing and to cultivate cloud computing talent.

ZStack provides innovative cloud infrastructure for ten major industries

The report provides three major
solutions and customer case studies for transitioning from VMware to ZStack.
In an era of rapid artificial intelligence advancement, every technological leap is like dropping a massive stone into the industry lake, stirring up countless ripples. On January 20, 2025, DeepSeek-R1 made a stunning debut, instantly igniting excitement in the AI community and becoming the center of attention. The outstanding performance of DeepSeek-R1 sparked widespread discussion, and we’re sure you’re curious about it. So, what logic drives the creation of these models? How are they trained? What differences exist between models, and which scenarios suit each one? Today, we’ll use the simplest, clearest language to quickly reveal the remarkable strengths of DeepSeek-R1.
The journey of DeepSeek models reflects a blend of innovation and evolution, culminating in the powerful R1 series. Let’s break it down step by step.
Recently, DeepSeek gained global attention with R1. Let’s briefly trace the timeline of DeepSeek’s model evolution:
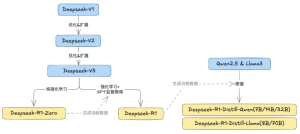
DeepSeek-R1 isn’t a product of one or two training methods stacked together. It evolved from V1 through multiple versions. Each built on the last, merging various training approaches. What’s more, DeepSeek-R1 embraces open-source principles. It’s freely available to global developers. This lowers barriers for researchers and businesses to use cutting-edge models. It drives global AI progress. Turing Award winner and Facebook’s Chief AI Scientist Yann LeCun praised it as “open-source triumphing over closed-source.”
DeepSeek-R1’s massive parameter size demands high deployment resources. To bring long-chain reasoning to smaller models, the DeepSeek team adopted distillation. Think of model distillation as a knowledge handover. Let’s use DeepSeek-R1-Distill-Qwen2.5-7B as an example to explain the process simply:
Model distillation offers several benefits. From a cost and efficiency standpoint, small distilled models can nearly match large models’ performance. This cuts enterprise deployment costs and speeds up reasoning. It also reduces reliance on massive computing resources. However, since it’s still fundamentally Qwen or Llama, careful understanding and testing are needed to meet real-world business needs.
Another key technique for efficient model operation is “quantization,” which we’ll explore next.
As mentioned, the true DeepSeek-R1 is a 671B-parameter version (often called the “full-power” version online). Yet, many tutorials guide users to download a distilled and fine-tuned Qwen2.5 7B via “ollama run deepseek-r1.” This version’s “intelligence” differs greatly from the model on DeepSeek’s official site. Look closely—it’s just 4.7GB. This indicates heavy quantization. Such compression further weakens its “intelligence.”
Quantization converts a model’s weights and activations from high precision (e.g., FP32, BF16) to low precision (e.g., INT8 or INT4). By reducing bit width per parameter, it slashes storage and computation needs. Quantized models cut memory use and processing demands. This enables large model deployment on standard GPUs or even CPUs. However, excessive quantization may harm accuracy, especially for tasks needing precise computation and reasoning.
For reasoning models, outputs often involve long token sequences and demand high precision. Thus, FP16 or INT8 quantization is advised. These methods reduce resource needs while largely preserving model performance.
Note that new quantization tools (e.g., Llama.cpp) offer fine-tuned processing. For example, they apply varied precision (4-bit, 6-bit, 32-bit) to different layers. This creates options like Q4_K_M or Q6. Still, it’s all about balancing accuracy, speed, and resource use.
DeepSeek’s original models are huge. Even at Int4, memory needs remain high. The MoE architecture and reasoning models add quantization challenges. Advanced methods like 1.58 or 2.51 mixed quantization or dynamic quantization can help. We’ll detail their effects and context quantization in later articles.
Yet, even after quantization, memory might fall short. Or outputs might truncate during runtime. This ties into another vital model factor: the “context window.”
The model stops before finishing its reasoning. Its output hits the “maximum length” limit. For DeepSeek’s official API, the max reasoning chain is 32K, with a max output of 8K. The original model supports up to 164K context—roughly 100,000 to 160,000 words total. But such long contexts consume vast resources. So, some APIs limit max output and context. Older non-reasoning models might manage with 4K context per chat. However, reasoning models use context for “thinking.” Thus, 4K often isn’t enough for one session, frustrating users.
A context window is the max token count a model can handle in one reasoning pass. Token-to-word ratios vary slightly by model. Longer contexts let models recall and grasp more text. This matters for long text generation and complex tasks, like large-scale code creation or expert content analysis.
Model memory use includes:
These are estimates using BF16 precision. FP8-supporting GPUs may differ. Context usage is calculated via llama.cpp; frameworks like vllm may use more. Concurrent requests need extra KV Cache per session.
Actual performance varies by hardware and optimization level. In this test, at 16 concurrent users, throughput peaked. Each user got ~42 tokens/second, with first-token latency under 0.2 seconds.
MMLU (Massive Multitask Language Understanding) benchmarks multi-task comprehension. We compared the 7B model’s MMLU scores pre- and post-distillation.
Post-distillation, scores dropped, and reasoning time notably lengthened.
We tested classic logic problems:
We tested RAG with DeepSeek V3 and R1 reports (22 pages, 8802 words; 53 pages, 22330 words) in AIOS’s Dify knowledge base. These weren’t in pre-training data, forcing comprehension-based answers. No prompt tweaks; 8K context; default settings. Answers were averaged over multiple queries.
Thanks to ZStack AIOS’s optimized environment, document vectorization and responses were swift. Results showed:
In future articles, we’ll explore:
By comparing sizes and precisions, we aim to offer detailed enterprise deployment plans. This will help industries adopt large language models swiftly, unlocking business value.
Starting with DeepSeek’s evolution, this article explored distillation and quantization’s roles in deployment. Through data and tests, we saw the distilled 7B model balance reasoning and cost well. We hope this provides useful insights for enterprise large language model use. Curious about 32B or 671B model deployment and evaluation? Stay tuned for our next articles!
 2025-02-05
2024-12-12
2024-10-24
2024-09-21
2024-10-10
2025-02-05
2024-12-12
2024-10-24
2024-09-21
2024-10-10